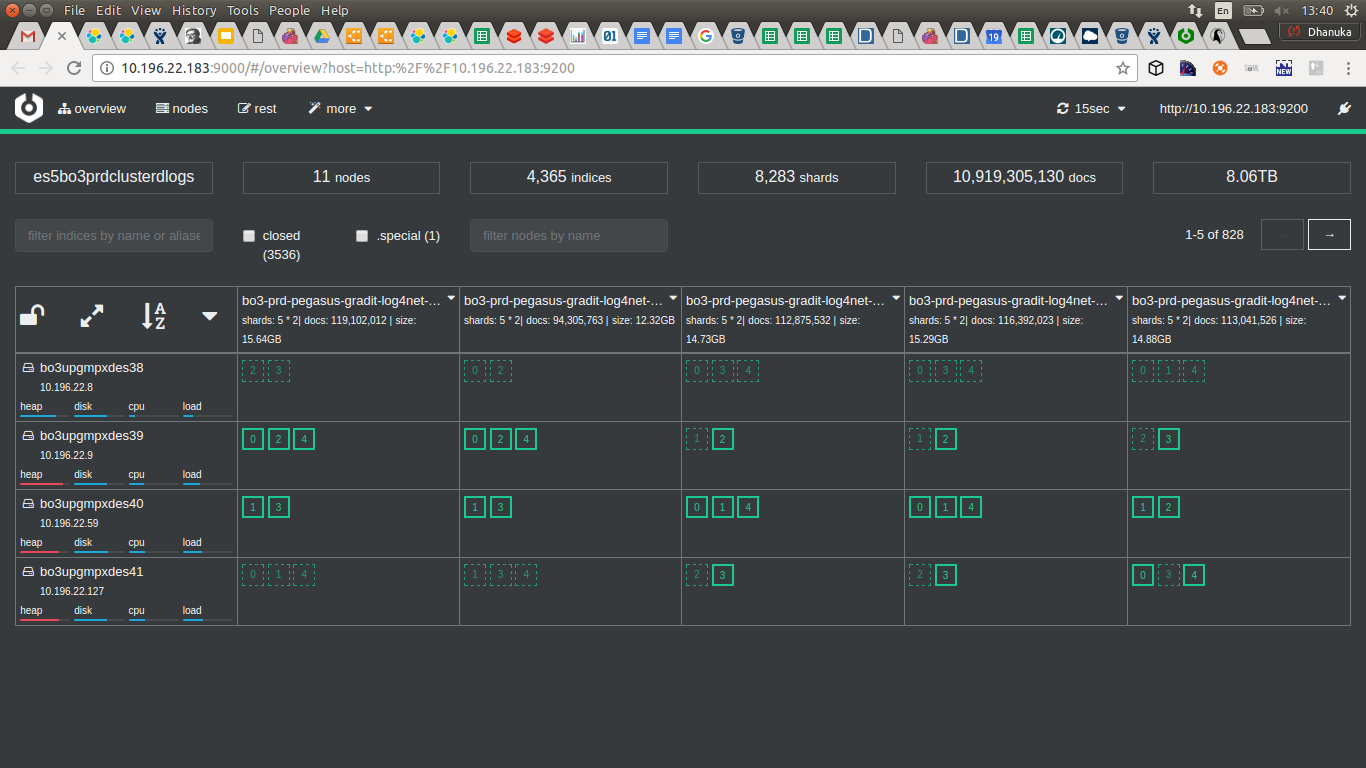
We used Elasticsearch as centralize logging system for multiple products.
Observations:
1. 8283 primary shards
2. 10 Billion documents
3. 8.06 TB of data in each data node
4. 4365 indices
5. Five primary shards per index
6. Four Data Nodes
7. Three out of four data nodes heap memory in critical state.
Identified drawbacks
- Use daily index creation for even 1GB size indexes.
- The default primary shard count for every index is 5.
- For 12 different indices, number of primary shards will be as follows.
(primary shard per index) * 12 (number of indexes/ products) * 30 (days per month) = 1800
(3 months) 1800 * 3 = 5400
(6 months) 1800 * 6 = 10800
Improvements
Use monthly index creation or create index more configurable manner based on the primary shard size.
Note: According to Elastic , recommended size of a primary shard is 30GB - 40GB (depend on network bandwidth)
number of shards per node below 20 to 25 per GB (roughly each primary shard cost 40 MB of heap memory)
5 * 6 * 11 + 5 * 30 = 480 (No of primary shards count)
Improvement = 10800/480 = 22.5 times
Clear some misunderstanding
According to Elastic these are the ratio between RAM & Storage for two main purposes (reading & writing).
For memory-intensive search workloads, more RAM (less storage) can improve performance. Use high-performance SSDs drives
For memory-intensive search workloads, more RAM (less storage) can improve performance. Use high-performance SSDs drives
and a RAM-to-storage ratio for users of 1:16 (or even 1:8). For example, if you use a ratio of 1:16, a cluster with 4GB of RAM will
get 64GB of storage allocated to it.
For logging workloads, more storage space can be more cost effective. Use a RAM-to-storage ratio of 1:48 to 1:96, as data sizes are
typically much larger compared to the RAM needed for logging. A cost effective solution might be to step down from SSDs to spinning
media, such as high-performance server disks. For example, if you use a ratio of 1:96, a cluster with 4GB of RAM will get 384 of
storage allocated to it.
If we take one of our ES based centralize Logs cluster in production it’s working fine for 8.5 TB data just for 25GB RAM in data nodes.
So according to Logs Cluster, RAM to Disk ratio is as 1:348. Also when we check number of primary shards it’s > 7000 .
So according to Logs Cluster, RAM to Disk ratio is as 1:348. Also when we check number of primary shards it’s > 7000 .
How can this happen, so Logs even work with less RAM??
Highest contribution made by one of the product logs, roughly daily index size is 30 GB. Most of other products generate less than
2 GB size of daily indexes.
2 GB size of daily indexes.
As we all know , the Logs Cluster query load is really low compared to logs writing frequency.Having said that , If we take biggest
logs contribution product logs writing frequency it’s
logs contribution product logs writing frequency it’s
something around 600 per second.
This is really low log writing load. According to my understanding normal workload should be 10000 per second.
So Elastic give recommendation keeping these workloads in mind, where our case this is really low situation and that’s why we still
can live with current RAM to Storage ratio.
So Elastic give recommendation keeping these workloads in mind, where our case this is really low situation and that’s why we still
can live with current RAM to Storage ratio.
References: