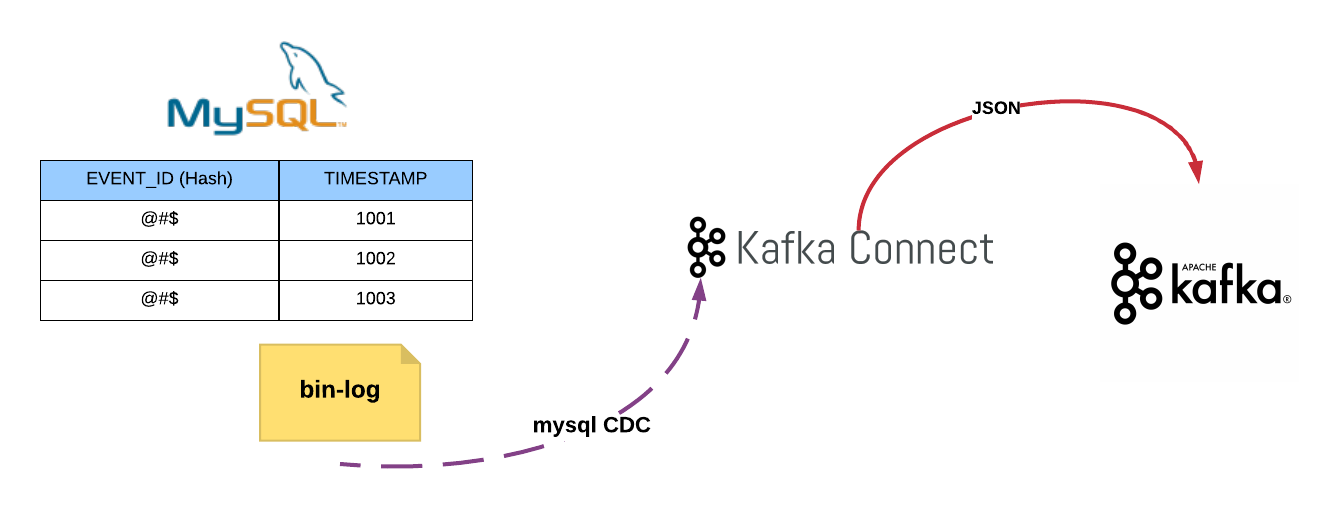
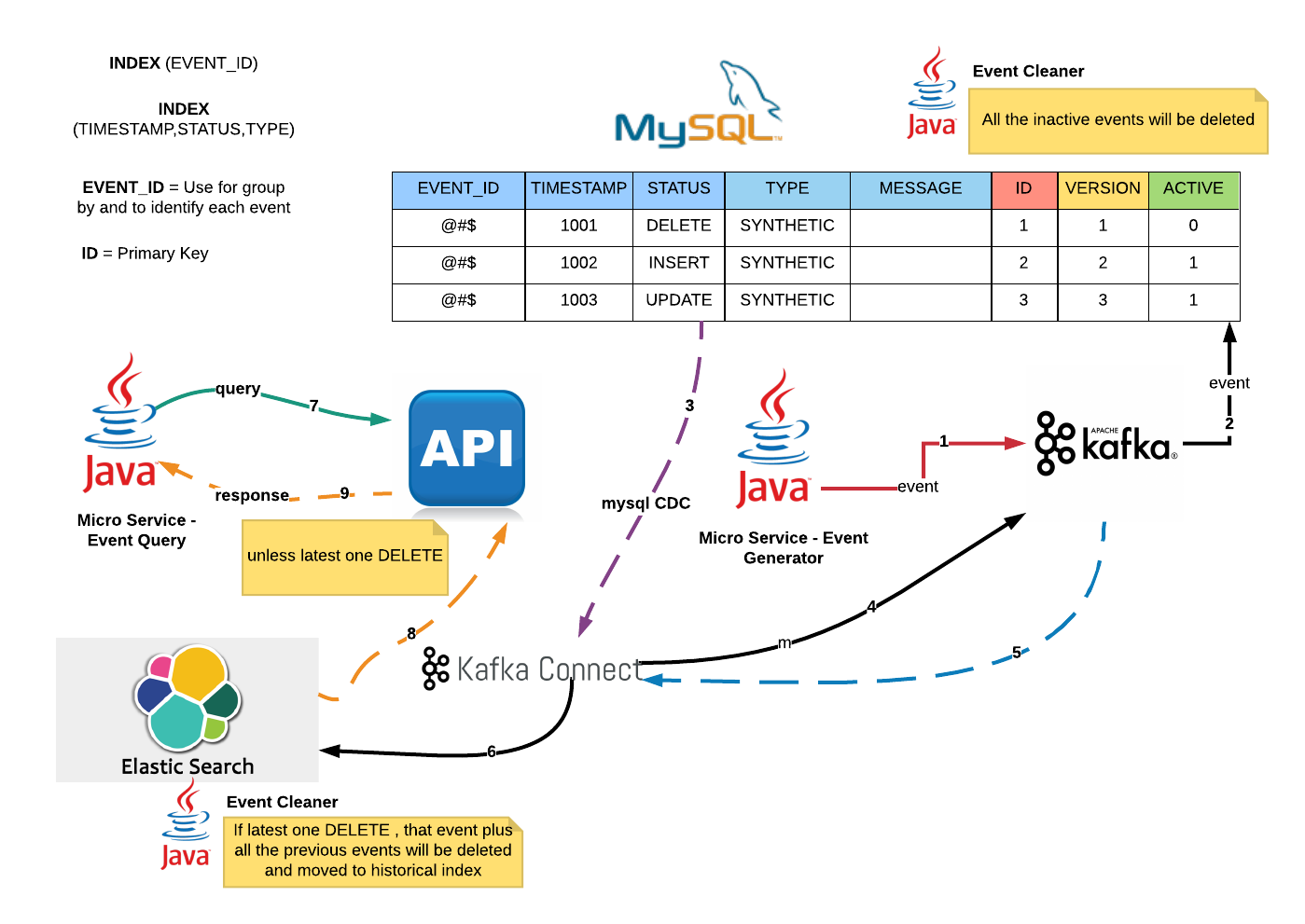
Software & tools you need to setup
1. Install MySql 5.7 in your local machine.
2. JDK 1.8
3. Maven
4. Confluent platform 3.2.2
5. Download below JARs from maven repository (https://mvnrepository.com/artifact)
debezium-core-0.5.2.jar,
debezium-connector-mysql-0.5.2.jar,
mysql-binlog-connector-java-0.9.2.jar ,
mysql-connector-java-5.1.40.jar,
protobuf-java-2.6.1.jar, wkb-1.0.2.jar
Steps:
1. Enable bin-log in mysql and create database and table in mysql
- Go to /etc/mysql/mysql.conf.d folder
Open and add below lines to mysqld.cnf file
#bin logs
server-id = 223344
log_bin = mysql-bin
binlog_format = row
binlog_row_image = full
expire_logs_days = 1
log-bin-index = bin-log.index
Restart mysql
$ /etc/init.d/mysql stop
$ /etc/init.d/mysql start
Create mysql db and table
$ mysql -u root -p root
mysql> create database eventsource;
mysql> DROP TABLE IF EXISTS `CMDB_TAG`;
CREATE TABLE `CMDB_TAG` (
`VERSION` bigint(20) DEFAULT NULL,
`TAG_KEY` varchar(255),
`TAG_VALUE` varchar(255),
PRIMARY KEY (`TAG_KEY`, `TAG_VALUE`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
2. Create mysql user with proper privileges
$ mysql -u root -p root
mysql> GRANT SELECT, RELOAD, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'debezium' IDENTIFIED BY 'dbz';
3. Start Zookeeper
$ cd ~/software/confluent-3.2.2
confluent-3.2.2$ nohup ./bin/zookeeper-server-start ./etc/kafka/zookeeper.properties &
4. Start Kafka
confluent-3.2.2$ nohup ./bin/kafka-server-start ./etc/kafka/server.properties > kafka.log 2>&1 &
Create kafka topic named events
confluent-3.2.2$ bin/kafka-topics --create --zookeeper localhost:2181 --replication-factor 3 --partitions 6 --topic events --config min.insync.replicas=2 --config unclean.leader.election.enable=false
5. Setup mysql kafka connector
Create directory called kafka-connect-cdc within confluent
confluent-3.2.2$ cd share/java
$ mkdir kafka-connect-cdc
Rename debezium-connector-mysql-0.5.2.jar as kafka-connect-cdc.jar
$ mv debezium-connector-mysql-0.5.2.jar as kafka-connect-cdc.jar
Copy all the downloaded jar into kafka-connect-cdc directory
confluent-3.2.2/share/java/kafka-connect-cdc$ ls
debezium-core-0.5.2.jar kafka-connect-cdc.jar mysql-binlog-connector-java-0.9.2.jar mysql-connector-java-5.1.40.jar protobuf-java-2.6.1.jar wkb-1.0.2.jar
Configure Connector
Go to etc folder
$ cd etc
Create directory called kafka-connect-cdc
$ mkdir kafka-connect-cdc
Create property file called kafka-connect-cdc.properties
$ touch kafka-connect-cdc.properties
Copy below content to kafka-connect-cdc.properties file
name=mysql-source
connector.class=io.debezium.connector.mysql.MySqlConnector
database.hostname=localhost
database.port=3306
database.user=debezium
database.password=dbz
server.id=223344
database.server.name=eventsource
database.history.kafka.bootstrap.servers=localhost:9092
database.whitelist=eventsource
database.history.kafka.topic=events
tasks.max=10
Start mysql cdc connector
confluent-3.2.2$ nohup ./bin/connect-standalone etc/kafka/connect-standalone.properties etc/kafka-connect-cdc/kafka-connect-cdc.properties > jdbc.log 2>&1 &
6. List Kafka topics
confluent-3.2.2$ bin/kafka-topics --zookeeper localhost:2181 --list
__consumer_offsets
events
eventsource
eventsource.eventsource.CMDB_TAG
- You can see that connector has created, two topics which is highlighted in yellow color.
7. Consume JSON messages from Kafka
confluent-3.2.2$ bin/kafka-console-consumer --bootstrap-server localhost:9092 --topic eventsource.eventsource.CMDB_TAG
8. Testing the Connector
Do some CRUD operation on table that we have created
mysql> use eventsource;
mysql> insert into CMDB_TAG (VERSION,TAG_KEY,TAG_VALUE) values(0,'TEST4','TEST1');
update CMDB_TAG set VERSION = 1 where TAG_KEY = 'TEST4' and TAG_VALUE = 'TEST1';
delete from CMDB_TAG where TAG_KEY = 'TEST4' and TAG_VALUE = 'TEST1';
From Kafka consumer console you can see following JSON messages.
{"schema":{"type":"struct","fields":[{"type":"struct","fields":[{"type":"int64","optional":true,"field":"VERSION"},{"type":"string","optional":false,"field":"TAG_KEY"},{"type":"string","optional":false,"field":"TAG_VALUE"}],"optional":true,"name":"eventsource.eventsource.CMDB_TAG.Value","field":"before"},{"type":"struct","fields":[{"type":"int64","optional":true,"field":"VERSION"},{"type":"string","optional":false,"field":"TAG_KEY"},{"type":"string","optional":false,"field":"TAG_VALUE"}],"optional":true,"name":"eventsource.eventsource.CMDB_TAG.Value","field":"after"},{"type":"struct","fields":[{"type":"string","optional":false,"field":"name"},{"type":"int64","optional":false,"field":"server_id"},{"type":"int64","optional":false,"field":"ts_sec"},{"type":"string","optional":true,"field":"gtid"},{"type":"string","optional":false,"field":"file"},{"type":"int64","optional":false,"field":"pos"},{"type":"int32","optional":false,"field":"row"},{"type":"boolean","optional":true,"field":"snapshot"},{"type":"int64","optional":true,"field":"thread"},{"type":"string","optional":true,"field":"db"},{"type":"string","optional":true,"field":"table"}],"optional":false,"name":"io.debezium.connector.mysql.Source","field":"source"},{"type":"string","optional":false,"field":"op"},{"type":"int64","optional":true,"field":"ts_ms"}],"optional":false,"name":"eventsource.eventsource.CMDB_TAG.Envelope","version":1},"payload":{"before":null,"after":{"VERSION":0,"TAG_KEY":"TEST4","TAG_VALUE":"TEST1"},"source":{"name":"eventsource","server_id":223344,"ts_sec":1527283334,"gtid":null,"file":"mysql-bin.000003","pos":1984,"row":0,"snapshot":null,"thread":5,"db":"eventsource","table":"CMDB_TAG"},"op":"c","ts_ms":1527283334083}}
{"schema":{"type":"struct","fields":[{"type":"struct","fields":[{"type":"int64","optional":true,"field":"VERSION"},{"type":"string","optional":false,"field":"TAG_KEY"},{"type":"string","optional":false,"field":"TAG_VALUE"}],"optional":true,"name":"eventsource.eventsource.CMDB_TAG.Value","field":"before"},{"type":"struct","fields":[{"type":"int64","optional":true,"field":"VERSION"},{"type":"string","optional":false,"field":"TAG_KEY"},{"type":"string","optional":false,"field":"TAG_VALUE"}],"optional":true,"name":"eventsource.eventsource.CMDB_TAG.Value","field":"after"},{"type":"struct","fields":[{"type":"string","optional":false,"field":"name"},{"type":"int64","optional":false,"field":"server_id"},{"type":"int64","optional":false,"field":"ts_sec"},{"type":"string","optional":true,"field":"gtid"},{"type":"string","optional":false,"field":"file"},{"type":"int64","optional":false,"field":"pos"},{"type":"int32","optional":false,"field":"row"},{"type":"boolean","optional":true,"field":"snapshot"},{"type":"int64","optional":true,"field":"thread"},{"type":"string","optional":true,"field":"db"},{"type":"string","optional":true,"field":"table"}],"optional":false,"name":"io.debezium.connector.mysql.Source","field":"source"},{"type":"string","optional":false,"field":"op"},{"type":"int64","optional":true,"field":"ts_ms"}],"optional":false,"name":"eventsource.eventsource.CMDB_TAG.Envelope","version":1},"payload":{"before":{"VERSION":0,"TAG_KEY":"TEST4","TAG_VALUE":"TEST1"},"after":{"VERSION":1,"TAG_KEY":"TEST4","TAG_VALUE":"TEST1"},"source":{"name":"eventsource","server_id":223344,"ts_sec":1527283762,"gtid":null,"file":"mysql-bin.000003","pos":2279,"row":0,"snapshot":null,"thread":5,"db":"eventsource","table":"CMDB_TAG"},"op":"u","ts_ms":1527283762079}}
{"schema":{"type":"struct","fields":[{"type":"struct","fields":[{"type":"int64","optional":true,"field":"VERSION"},{"type":"string","optional":false,"field":"TAG_KEY"},{"type":"string","optional":false,"field":"TAG_VALUE"}],"optional":true,"name":"eventsource.eventsource.CMDB_TAG.Value","field":"before"},{"type":"struct","fields":[{"type":"int64","optional":true,"field":"VERSION"},{"type":"string","optional":false,"field":"TAG_KEY"},{"type":"string","optional":false,"field":"TAG_VALUE"}],"optional":true,"name":"eventsource.eventsource.CMDB_TAG.Value","field":"after"},{"type":"struct","fields":[{"type":"string","optional":false,"field":"name"},{"type":"int64","optional":false,"field":"server_id"},{"type":"int64","optional":false,"field":"ts_sec"},{"type":"string","optional":true,"field":"gtid"},{"type":"string","optional":false,"field":"file"},{"type":"int64","optional":false,"field":"pos"},{"type":"int32","optional":false,"field":"row"},{"type":"boolean","optional":true,"field":"snapshot"},{"type":"int64","optional":true,"field":"thread"},{"type":"string","optional":true,"field":"db"},{"type":"string","optional":true,"field":"table"}],"optional":false,"name":"io.debezium.connector.mysql.Source","field":"source"},{"type":"string","optional":false,"field":"op"},{"type":"int64","optional":true,"field":"ts_ms"}],"optional":false,"name":"eventsource.eventsource.CMDB_TAG.Envelope","version":1},"payload":{"before":{"VERSION":1,"TAG_KEY":"TEST4","TAG_VALUE":"TEST1"},"after":null,"source":{"name":"eventsource","server_id":223344,"ts_sec":1527283970,"gtid":null,"file":"mysql-bin.000003","pos":2596,"row":0,"snapshot":null,"thread":5,"db":"eventsource","table":"CMDB_TAG"},"op":"d","ts_ms":1527283970341}}
{"schema":null,"payload":null}
- I have highlighted the db operations in pink color.
- Also once we delete a record we have received last JSON, which is highlighted in green.
References: