Apache Avro
Logs
Another way to put this is in database terms: a pure stream is one where the changes are interpreted as just
INSERT statements (since no record replaces any existing record),
INSERT statements (since no record replaces any existing record),
whereas a table is a stream where the changes are interpreted as UPDATEs (since any existing row with the same key is overwritten).
Paper
Article
Architecture
Big data messaging
Install zookeeper and kafka (horton works)
Simple consumer and producer app
Duality of stream & table + windowing
Kafka Connect sample
Partitions
When a producer published a message to the topic, it would assign a partition ID for that message.
The server would then append the message to the log file for that partition only.
If you then started two consumers, the server might assign partitions 1 and 2 to the first consumer, and partition 3 to the second consumer. Each consumer would read only from its assigned partitions.

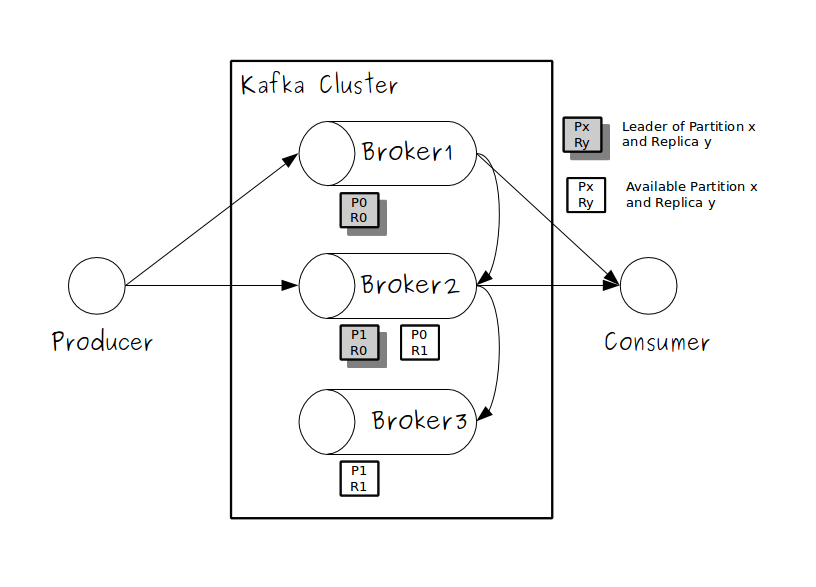
To expand the scenario, imagine a Kafka cluster with two brokers, housed in two machines. When you partitioned the demo topic, you would configure it to have two partitions and two replicas.
For this type of configuration, the Kafka server would assign the two partitions to the two brokers in your cluster.
Each broker would be the leader for one of the partitions.
When a producer published a message, it would go to the partition leader.
The leader would take the message and append it to the log file on the local machine.
The second broker would passively replicate that commit log to its own machine. If the partition leader went down, the second broker would become the new leader and start serving client requests.
In the same way, when a consumer sent a request to a partition, that request would go first to the partition leader, which would return the requested messages.
For this type of configuration, the Kafka server would assign the two partitions to the two brokers in your cluster.
Each broker would be the leader for one of the partitions.
When a producer published a message, it would go to the partition leader.
The leader would take the message and append it to the log file on the local machine.
The second broker would passively replicate that commit log to its own machine. If the partition leader went down, the second broker would become the new leader and start serving client requests.
In the same way, when a consumer sent a request to a partition, that request would go first to the partition leader, which would return the requested messages.
2. Active-Active

1. Scalability: In a system with just one partition, messages published to a topic are stored in a log file, Partitioning a topic lets you scale your system by storing messages on different machines in a cluster. If you wanted to store 30 gigabytes (GB) of messages for the Demo topic, for instance, you could build a Kafka cluster of three machines,each with 10 GB of disk space. Then you would configure the topic to have three partitions. which exists on a single machine.
The number of messages for a topic must fit into a single commit log file, and the size of messages stored can never be more than that machine's disk space.
2. Server-load balancing: Having multiple partitions lets you spread message requests across brokers. For example, If you had a topic that processed 1 million messages per second, you could divide it into 100 partitions and add 100 brokers to your cluster.
Each broker would be the leader for single partition, responsible for responding to just 10,000 client requests per second.
3. Consumer-load balancing: Similar to server-load balancing, hosting multiple consumers on different machine lets you spread the consumer load.
Let's say you wanted to consume 1 million messages per second from a topic with 100 partitions. You could create 100 consumers and run them in parallel.
The Kafka server would assign one partition to each of the consumers, and each consumer would process 10,000 messages in parallel.
Since Kafka assigns each partition to only one consumer, within the partition each message would be consumed in order.
Two partition two consumers under one user group
Two partition one producer three consumers under two user groups

Multi Threaded Consumer
Kafka Connect Architecture
Connector model
Worker model
Data model
Connector Model
A connector is defined by specifying a Connector class and configuration options to control what data is copied and how to format it.
Each Connector instance is responsible for defining and updating a set of Tasks that actually copy the data. Kafka Connect manages the Tasks;
the Connector is only responsible for generating the set of Tasks and indicating to the framework when they need to be updated.
Each Connector instance is responsible for defining and updating a set of Tasks that actually copy the data. Kafka Connect manages the Tasks;
the Connector is only responsible for generating the set of Tasks and indicating to the framework when they need to be updated.
Connectors do not perform any data copying themselves: their configuration describes the data to be copied,
and the Connector is responsible for breaking that job into a set of Tasks that can be distributed to workers.
and the Connector is responsible for breaking that job into a set of Tasks that can be distributed to workers.
Standalone mode

Distributed mode
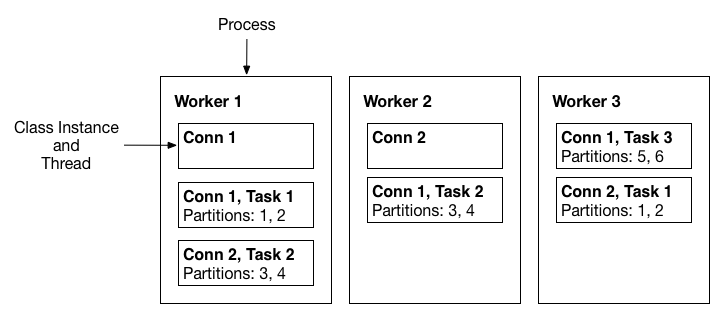
First, Kafka Connect performs broad copying by default by having users define jobs at the level of Connectors which then break the job into smaller Tasks.
It also provides one point of parallelism by requiring Connectors to immediately consider how their job can be broken down into subtasks, Finally, by specializing source and sink interfaces, Kafka Connect provides an accessible connector API that makes it very easy to implement connectors for a variety of systems.
It also provides one point of parallelism by requiring Connectors to immediately consider how their job can be broken down into subtasks, Finally, by specializing source and sink interfaces, Kafka Connect provides an accessible connector API that makes it very easy to implement connectors for a variety of systems.
Worker Model
each other to distribute work and provide scalability and fault tolerance. The Workers will distribute work among any available processes, but are not responsible for management of the processes; any process management strategy can be used for Workers (e.g. cluster management tools like YARN or Mesos, configuration management tools like Chef or Puppet, or direct management of process lifecycles).
The worker model allows Kafka Connect to scale to the application. It can run scaled down to a single worker process that also acts as its own coordinator, or in clustered mode where connectors and tasks are dynamically scheduled on workers.
However, it assumes very little about the process management of the workers, so it can easily run on a variety of cluster managers or using traditional service supervision.
Data Model
Each of these streams is an ordered set messages where each message has an associated offset
The message contents are represented by Connectors in a serialization-agnostic format, and Kafka Connect supports pluggable Converters for storing this data in a variety of serialization formats. Schemas are built-in, allowing important metadata about the format of messages to be propagated through complex data pipelines.
However, schema-free data can also be used when a schema is simply unavailable.
This allows Kafka Connect to focus only on copying data because a variety of stream processing tools are available to further process the data, which keeps Kafka Connect simple, both conceptually and in its implementation.
Kafka on Yarn (KOYA)
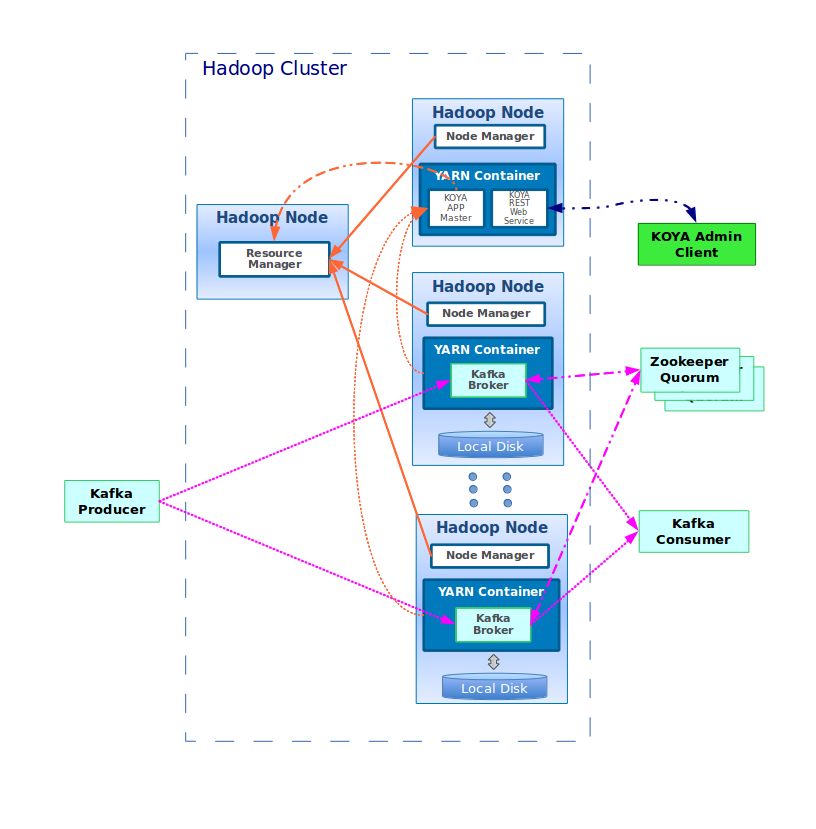
Why not confluent platform? It’s open source as well
Geo Redundancy
- Netflix Use case
2. Recommended approach (In same region)
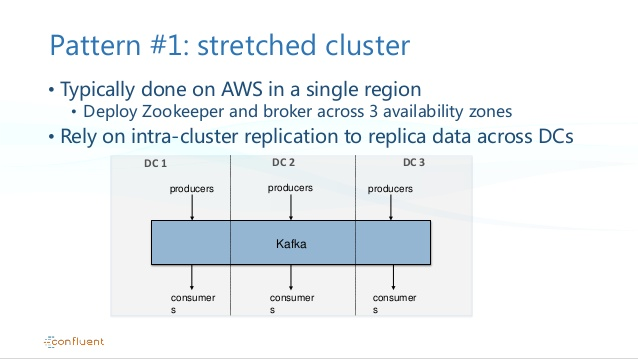

3. Best approach for Multi Region to avoid cycles
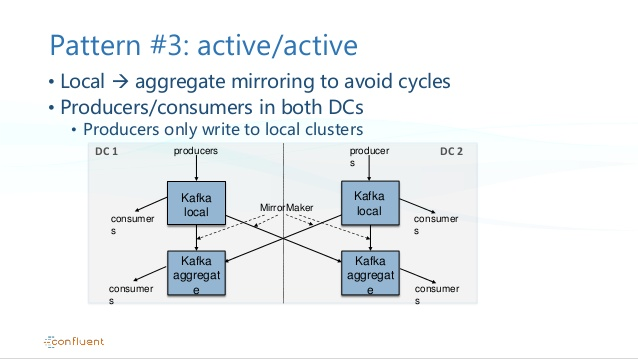
Mirror Message handling in Kafka to avoid cycling
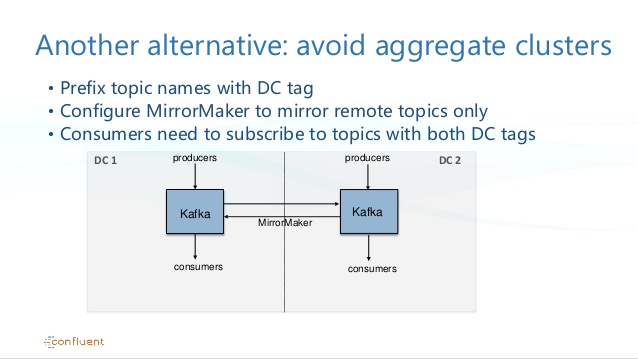
Master-Master replication
4. Kafka + ElasticSearch
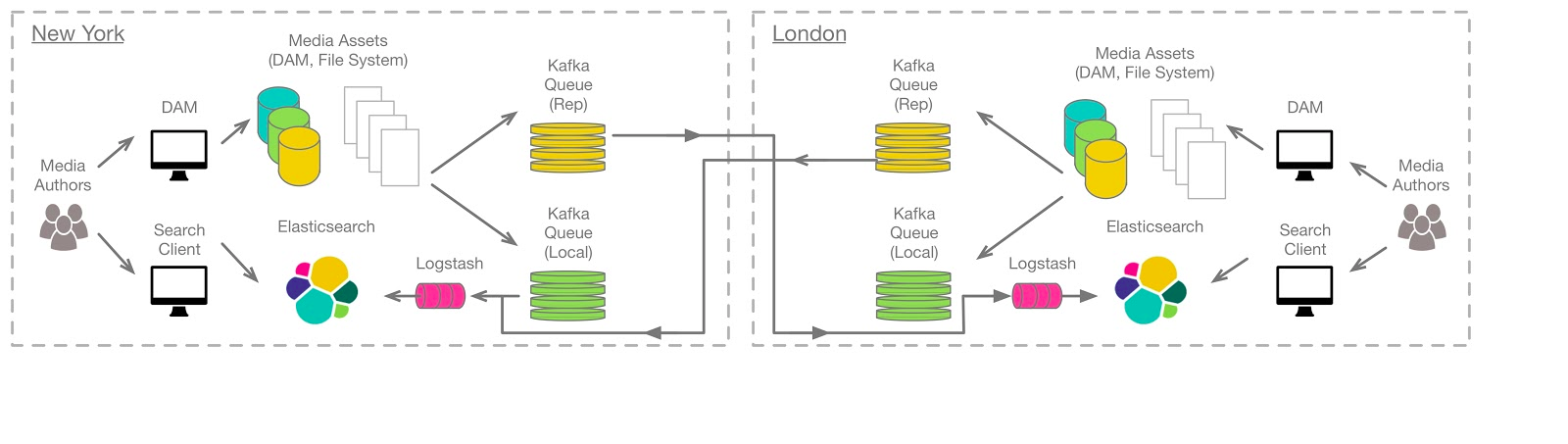
* Note: we can replace Logstash with Kafka Connect Sink Connector.
Mirror Maker
Important of mirror maker and improvements done with it
Some references
Message Handler sample
Kafka Messaging Semantics
Exactly one
Message compaction
Partitioning
Kafka tuning recommendation
Kafka Cluster
Kafka Cluster Deployment Recommendation
Dedicated Zookeeper
- Have a separate zookeeper cluster dedicated to Storm/Kafka operations. This will improve Storm/Kafka’s performance for writing offsets to Zookeeper,it will not be competing with HBase or other components for read/write access.
ZK on separate nodes from Kafka Broker
- Do Not Install zk nodes on the same node as kafka broker if you want optimal Kafka performance. Disk I/O both kafka and zk are disk I/O intensive.
Zookeeper recommendation:
Design Doc
Kafka Data Replication
Hard Problems
No comments:
Post a Comment