Supervised
Supervised learning is where you have input variables (x) and an output variable (Y) and you use an algorithm to learn the mapping function from the input to the output.
Y = f(X)
The goal is to approximate the mapping function so well that when you have new input data (x) that you can predict the output variables (Y) for that data.
Regression vs Classification
Regression is used to predict continuous values. Classification is used to predict which class a data point is part of (discrete value).
Regression
In the case of regression, the target variable is continuous — meaning that it can take any value within a specified range. Input variables, on the other hand, can be either discrete or continuous.
Linear Regression
Math:
SepalLength = a * PetalWidth + b* PetalLength +c
Code:
# Load required packages
library(ggplot2)
# Load iris dataset
data(iris)
# Have a look at the first 10 observations of the dataset
head(iris)
# Fit the regression line
fitted_model <- lm(Sepal.Length ~ Petal.Width + Petal.Length, data = iris)
# Get details about the parameters of the selected model
summary(fitted_model)
# Plot the data points along with the regression line
ggplot(iris, aes(x = Petal.Width, y = Petal.Length, color = Species)) +
geom_point(alpha = 6/10) +
stat_smooth(method = "lm", fill="blue", colour="grey50", size=0.5, alpha = 0.1)

Logistic Regression
The difference is that the regression line is not straight anymore.
Math:
Y=g(a*X1+b*X2)
...where g() is the logistic function.
Code:
# Load required packages
library(ggplot2)
# Load data
data(mtcars)
# Keep a subset of the data features that includes on the measurement we are interested in
cars <- subset(mtcars, select=c(mpg, am, vs))
# Fit the logistic regression line
fitted_model <- glm(am ~ mpg+vs, data=cars, family=binomial(link="logit"))
# Plot the results
ggplot(cars, aes(x=mpg, y=vs, colour = am)) + geom_point(alpha = 6/10) +
stat_smooth(method="glm",fill="blue", colour="grey50", size=0.5, alpha = 0.1, method.args=list(family="binomial"))

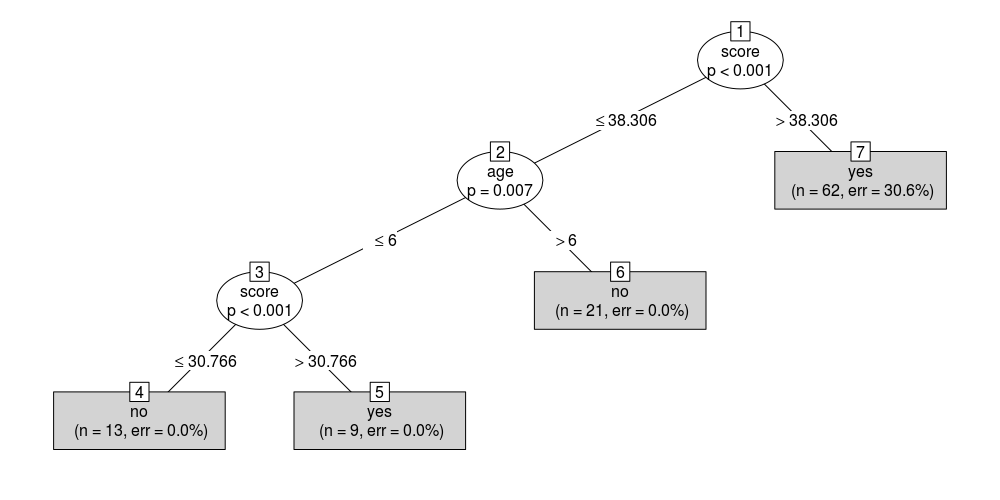
Decision Trees (Classification or Regression)
What they basically do is draw a “map” of all possible paths along with the corresponding result in each case.
Based on a tree like this, the algorithm can decide which path to follow at each step depending on the value of the corresponding criterion.
Code:
# Include required packages
#install.packages("party")
#install.packages("partykit")
library(party)
library(partykit)
# Have a look at the first ten observations of the dataset
print(head(readingSkills))
input.dat <- readingSkills[c(1:105),]
# Grow the decision tree
output.tree <- ctree(
nativeSpeaker ~ age + shoeSize + score,
data = input.dat)
# Plot the results
plot(as.simpleparty(output.tree))
Unsupervised
Unsupervised learning is where you only have input data (X) and no corresponding output variables.
The goal for unsupervised learning is to model the underlying structure or distribution in the data in order to learn more about the data.
These are called unsupervised learning because unlike supervised learning above there is no correct answers and there is no teacher. Algorithms are left to their own devises to discover and present the interesting structure in the data.
Clustering
With clustering, if we have some initial data at our disposal, we want to form groups so that the data points belonging to some group are similar and are different from data points of the other groups , such as grouping customers by purchasing behavior..
Algorythm :
- Initialization step: For k=3 clusters, the algorithm randomly selects three points as centroids for each cluster.
- Cluster assignment step: The algorithm goes through the rest of the data points and assigns each one of them to the closest cluster.
- Centroid move step: After cluster assignment, the centroid of each cluster is moved to the average of all points belonging to the cluster.
Steps 2 and 3 are repeated multiple times until there is no change to be made regarding cluster assignments.
Code:
# Load required packages
library(ggplot2)
library(datasets)
# Load data
data(iris)
# Set seed to make results reproducible
set.seed(20)
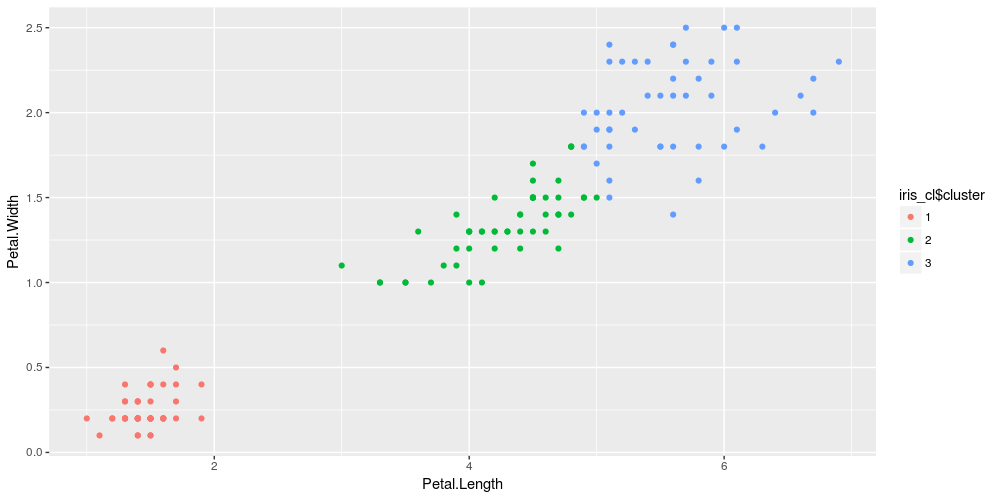
# Implement k-means with 3 clusters
iris_cl <- kmeans(iris[, 3:4], 3, nstart = 20)
iris_cl$cluster <- as.factor(iris_cl$cluster)
# Plot points colored by predicted cluster
ggplot(iris, aes(Petal.Length, Petal.Width, color = iris_cl$cluster)) + geom_point()
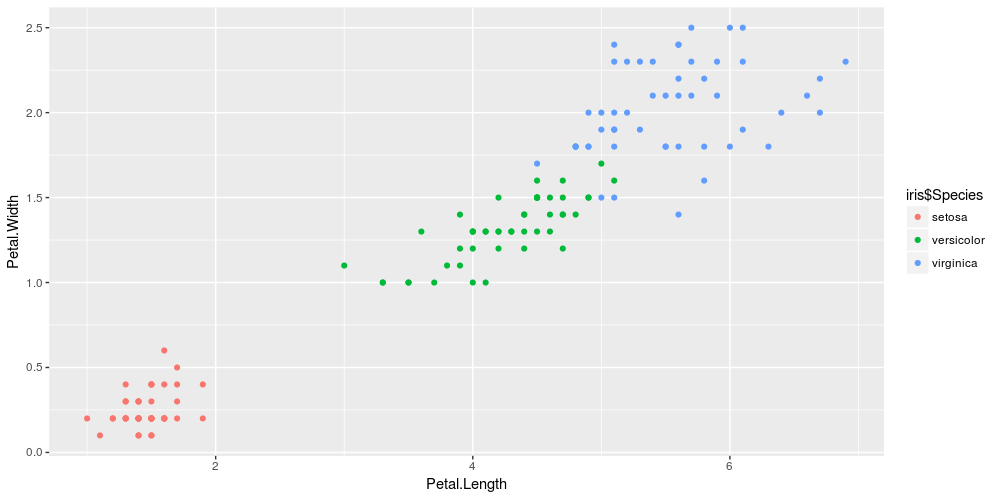
Colored by Species
Code:
# Load required packages
library(ggplot2)
library(datasets)
# Load data
data(iris)
# Set seed to make results reproducible
set.seed(20)
# Implement k-means with 3 clusters
iris_cl <- kmeans(iris[, 3:4], 3, nstart = 20)
iris_cl$cluster <- as.factor(iris_cl$cluster)
# Plot points colored by predicted cluster
ggplot(iris, aes(Petal.Length, Petal.Width, color = iris$Species)) + geom_point()
Association
An association rule learning problem is where you want to discover rules that describe large portions of your data, such as people that buy X also tend to buy Y.
References:
No comments:
Post a Comment